Bilingual Govt. Extraction
Seamlessly extracting data from Marathi/English 7/12 and 8-A forms with 100% precision.

OMCARA is a proprietary Windows-based innovation that eliminates manual typing. Using Structured™ Logic, we transform system generated and system printed PDFs and images into accurate, structured intelligence
Our proprietary engine for structured data extraction. It doesn't just "read" text; it understands document geometry to ensure zero-error retrieval.
OMCARA operates as a dedicated Windows-based hub, providing high-speed processing for PDFs, TIFFs, and JPGs without external lag.
Engineered by a software professional with a 20-year track record in S/w development, ETL processes, complex SQL triggers, and large-scale automation projects.
Submit your most complex system generated document (PDF File/Image) for a complimentary accuracy audit. Witness 100% data extraction precision powered by our proprietary structured Logic.
OMCARA is not just a software; it is the culmination of a 20-year journey through the most complex layers of data architecture. The inventor, a seasoned Full-Stack Professional, has spent such a huge tenure identifying the "hidden gaps" in how businesses process information
From the early days of mastering Windows Architecture and VB6 logic to leading large-scale ETL and Data Migration projects for global giants in Healthcare, Insurance, and Automotive sectors, the goal remained constant: The elimination of manual error
Having delivered over 100+ bespoke automation solutions, our founder recognized that traditional OCR was failing at the final hurdle—100% accuracy. This led to the birth of SARITA™ Logic, a proprietary intelligence engine that doesn't just read documents but understands their very geometry.
Began the journey in Pune as a Software Developer, mastering the core of Windows Architecture and the logic-driven world of VB6.
Advanced into Assistant Management, delivering complex automation solutions across Healthcare and Insurance sectors.
Stepped into Technical Leadership, managing intricate ETL processes and data migrations for multi-national industrial projects.
The Vision of OMCARA; After 16+ years of full-stack expertise and 100+ bespoke solutions, transitioned to a Senior Lead role to finalize the proprietary SARITA™ Logic.
Today, OMCARA stands as a testament to this technical pedigree—a standalone Windows innovation designed to transform document chaos into structured digital excellence.

To redefine the global standards of data entry by replacing manual efforts with 100% accurate, automated intelligence. We aim to empower organizations to convert their unstructured document chaos into structured, actionable data assets using our standalone Windows-based innovation.
To be the world’s most trusted standalone engine for document intelligence. We envision a future where SARITA™ Logic serves as the universal bridge between physical documentation and digital excellence, ensuring zero data loss and maximum organizational value.
OMCARA represents the definitive evolution of document intelligence, born from two decades of solving complex data challenges for global giants. By fusing foundational mastery in Windows architecture with the proprietary precision of SARITA™ Logic, we have eliminated the margin for human error in data entry. Our innovation serves as a battle-tested bridge between legacy document chaos and modern automated excellence. We don't just process information; we engineer the absolute accuracy required for the next generation of industrial growth
Utilizing proprietary anchor-point logic to ensure 100% structural integrity. The data you see is exactly the data you get, with zero character drifting.
Democratizing high-end data extraction so even the smallest business can operate with enterprise-level efficiency and reclaimed human potential.
Moving beyond sequential processing. OMCARA works broader by analyzing entire batches of files simultaneously, consolidating hundred of data points in seconds
Serving as a digitally integrated bridge between static document repositories and dynamic Business Intelligence to drive a high-yield ROI
Seamlessly process and extract high-quality data from a wide range of formats, including BMP, JPG, JPEG, PNG, and PDF


Specify custom templates to define precise Key-Value pairs, ensuring specific data points are retrieved from the exact location they appear.
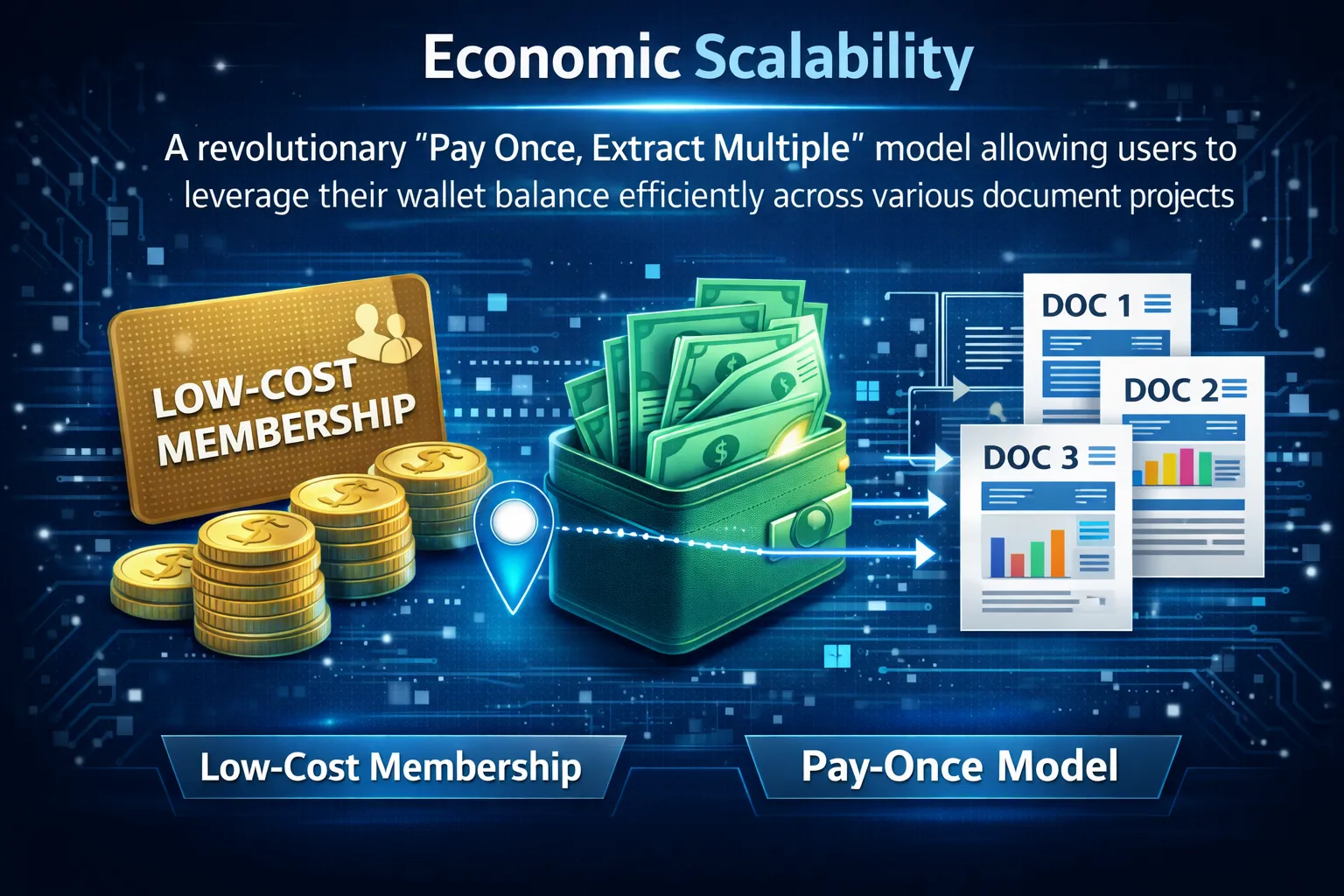
A revolutionary "Pay Once, Extract Multiple" model allowing users to leverage their wallet balance efficiently across various document projects.

Eliminate manual entry errors by exporting verified, structured intelligence directly into Microsoft Excel for immediate analysis
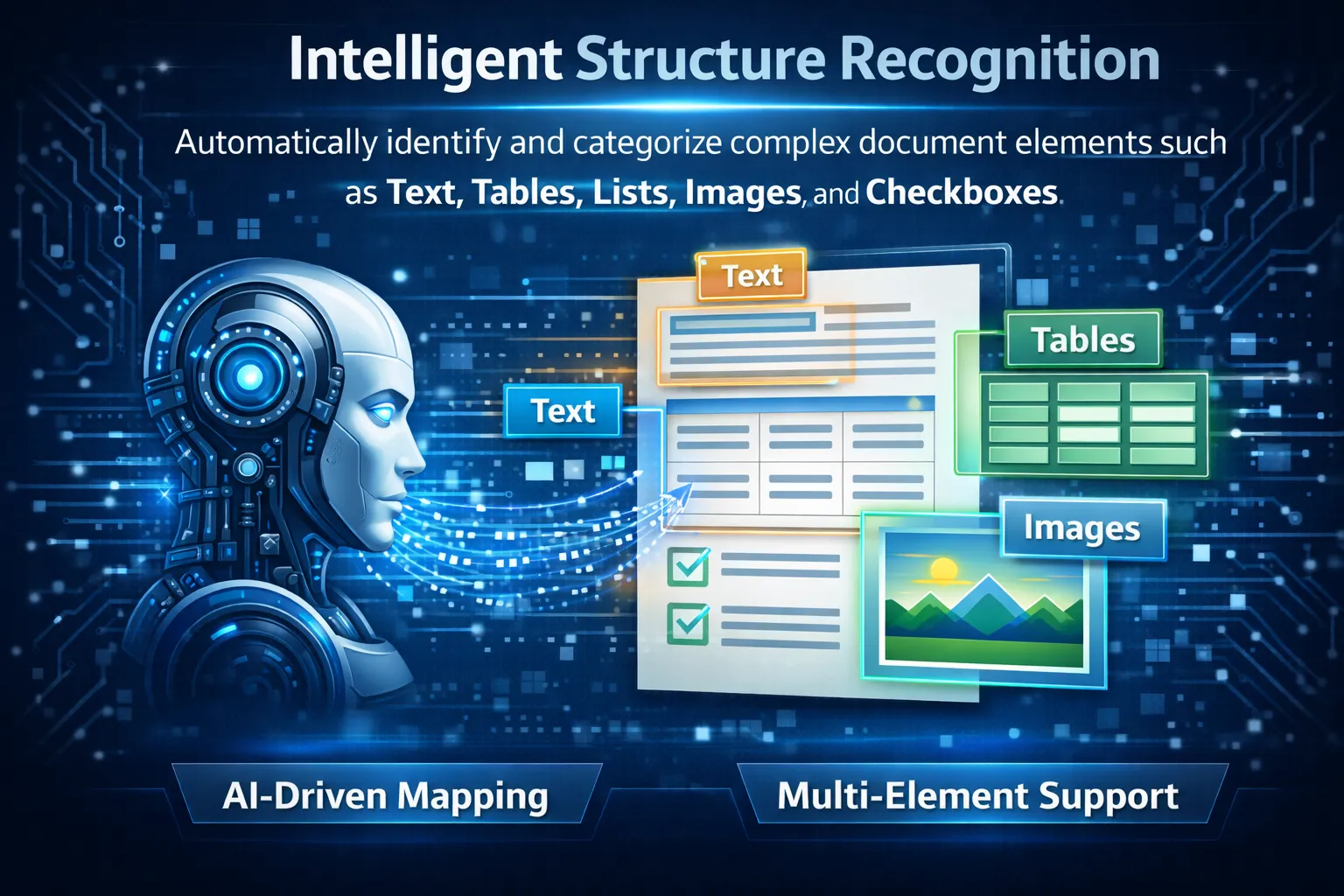
Automatically identify and categorize complex document elements such as Text, Tables, Lists, Images, and Checkboxes
Manual data entry is no longer sustainable. We identify the bottlenecks in your workflow to pave the way for 100% automated precision
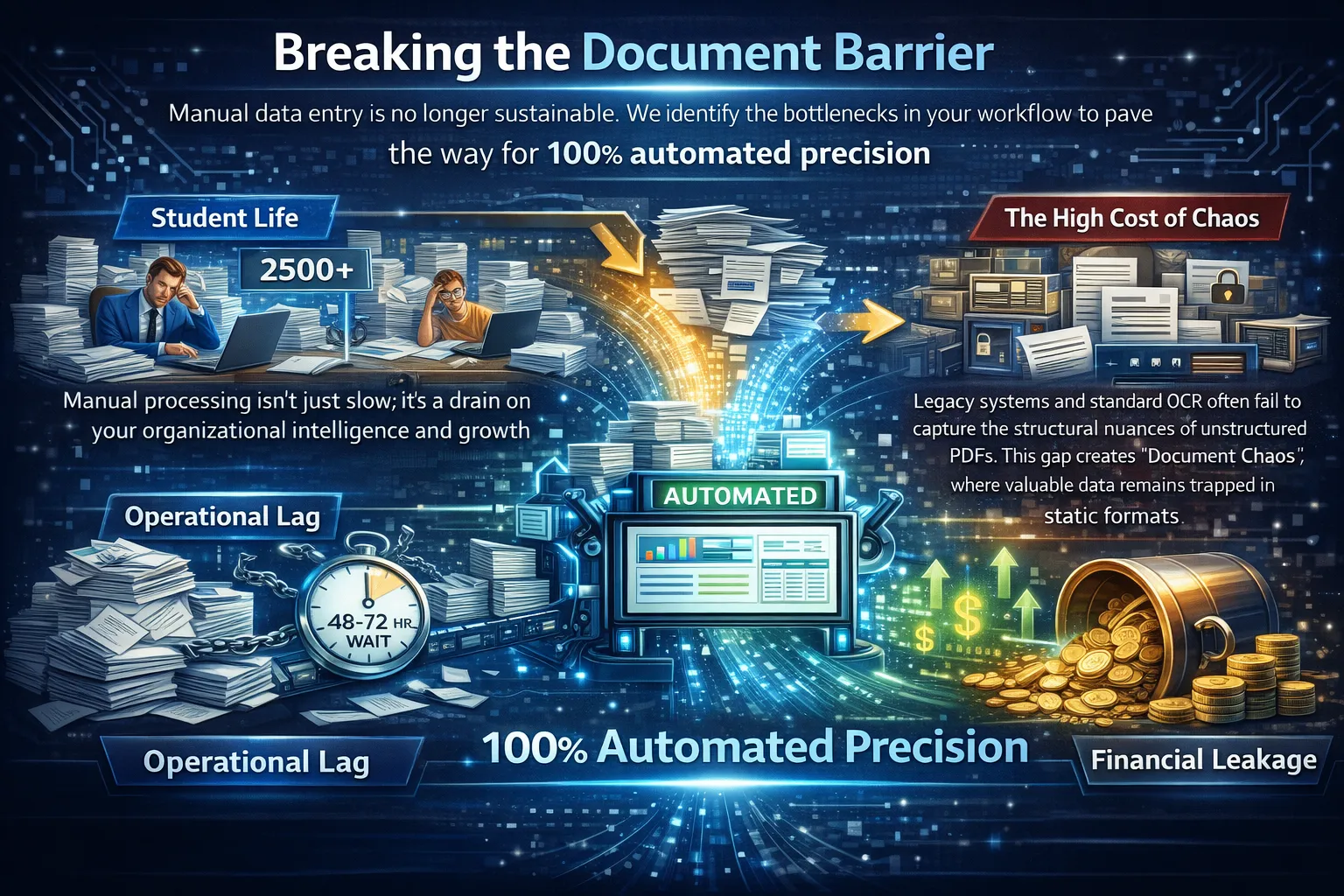
Legacy systems and standard OCR often fail to capture the structural nuances of unstructured PDFs. This gap creates "Document Chaos," where valuable data remains trapped in static formats


Moving beyond "probabilistic" OCR to deterministic extraction using SARITA™ Logic for 100% accuracy.

Specialized in the "tough stuff"—scanned images, multi-page TIFFs, and non-linear PDF layouts.

Direct integration into SQL, Excel, or Cloud DBs, turning document chaos into a Profit-Driving Asset.
Standard OCR often provides only a probabilistic 'best guess' of text, leading to character drift and data loss. OMCARA introduces a deterministic approach using SARITA™ Logic, ensuring that every data point—from complex tables to bilingual land records—is extracted with absolute structural integrity
Eliminating manual verification through deterministic anchor-point logic
Seamlessly processing PDF, TIFF, JPG, JPEG, PNG, and BMP in a single hub
Consolidating thousands of pages into a single structured output
A standalone Windows hub ensuring maximum data privacy and speed
Automating high-volume data entry to reduce operational lag and human error
Streamlining mediclaim investigations and patient records with 100+ column precision
Handling complex bilingual (Marathi/English) document extractions like 7/12 and 8-A forms
Scaling service delivery through a "Pay Once, Extract Multiple" economic model
Mapping unstructured invoices and KYC documents directly into structured SQL/Excel databases
OMCARA isn't just a tool; it’s a productivity multiplier. By bridging the gap between unstructured document chaos and modern Business Intelligence, we empower organizations to reclaim their human potential and turn static files into profit-driving assets.



Industrial Use-Cases & Strategic Impact; Versatility of OMCARA

Seamlessly extracting data from Marathi/English 7/12 and 8-A forms with 100% precision.
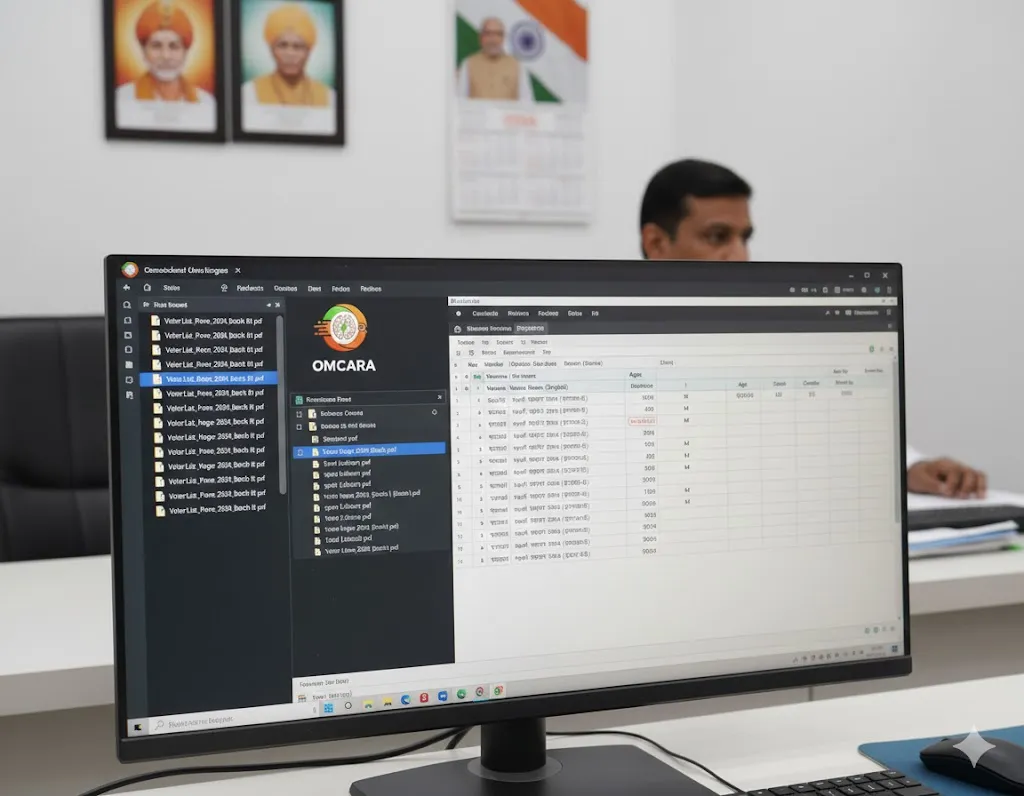
Batch processing 1000+ multi-page PDFs to structure thousands of voter entries per hour.


Automating n number of columns data intake for mediclaim investigations and patient history records.


Mapping unstructured parts invoices and shipment logs directly into ERP and SQL databases.


Retrieving complex tabular data including caste, religion, and occupation from manual records.

Converting unstructured ID proofs and financial statements into verified, searchable digital assets.
OMCARA combines the power of a Windows-based UI with a secure Linux VPS backend. We provide users with absolute control over their data through ephemeral storage protocols and permanent deletion provisions
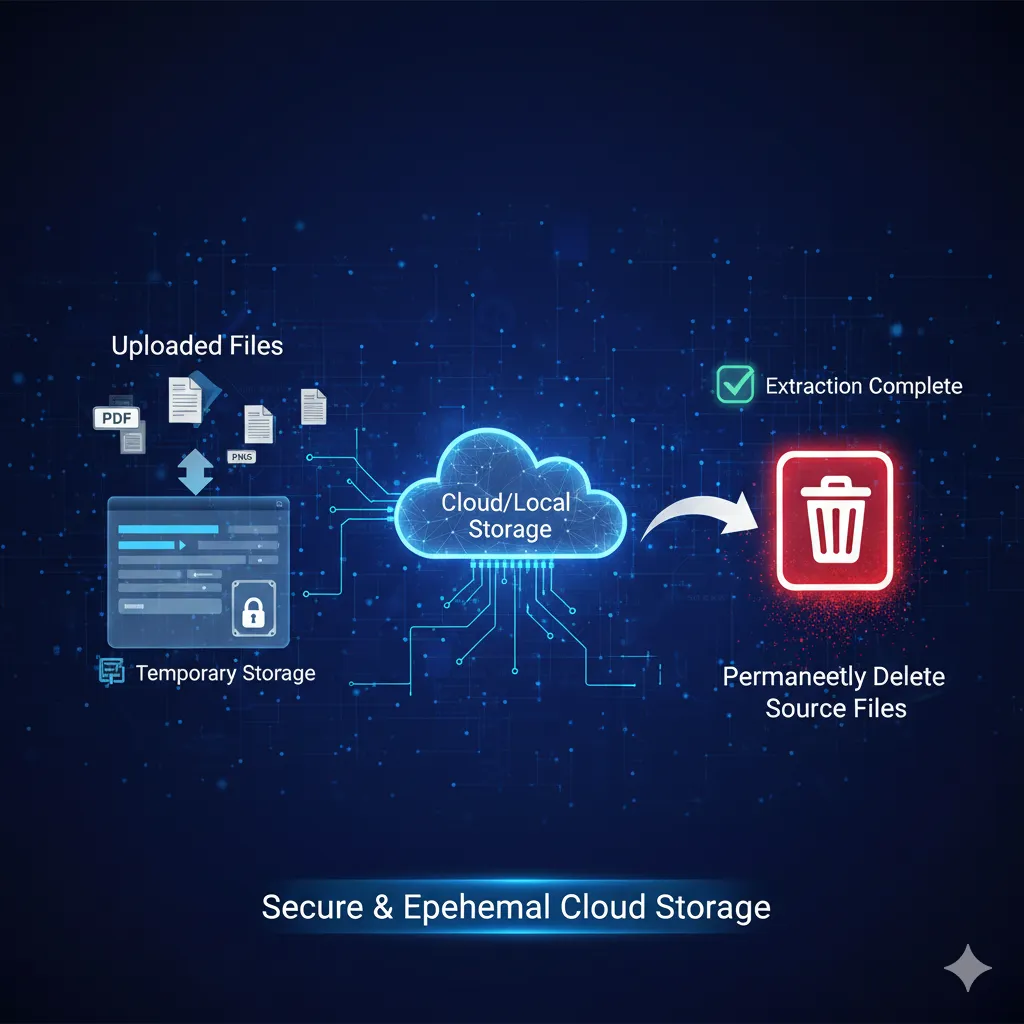
Uploaded files are stored in dynamically created temporary storage on the cloud/local. Users have the provision to permanently delete all source files once extraction is complete.

Leveraging a 19-year legacy in Windows Architecture integrated with a high-performance Python API hosted on a secure Virtual Private Server
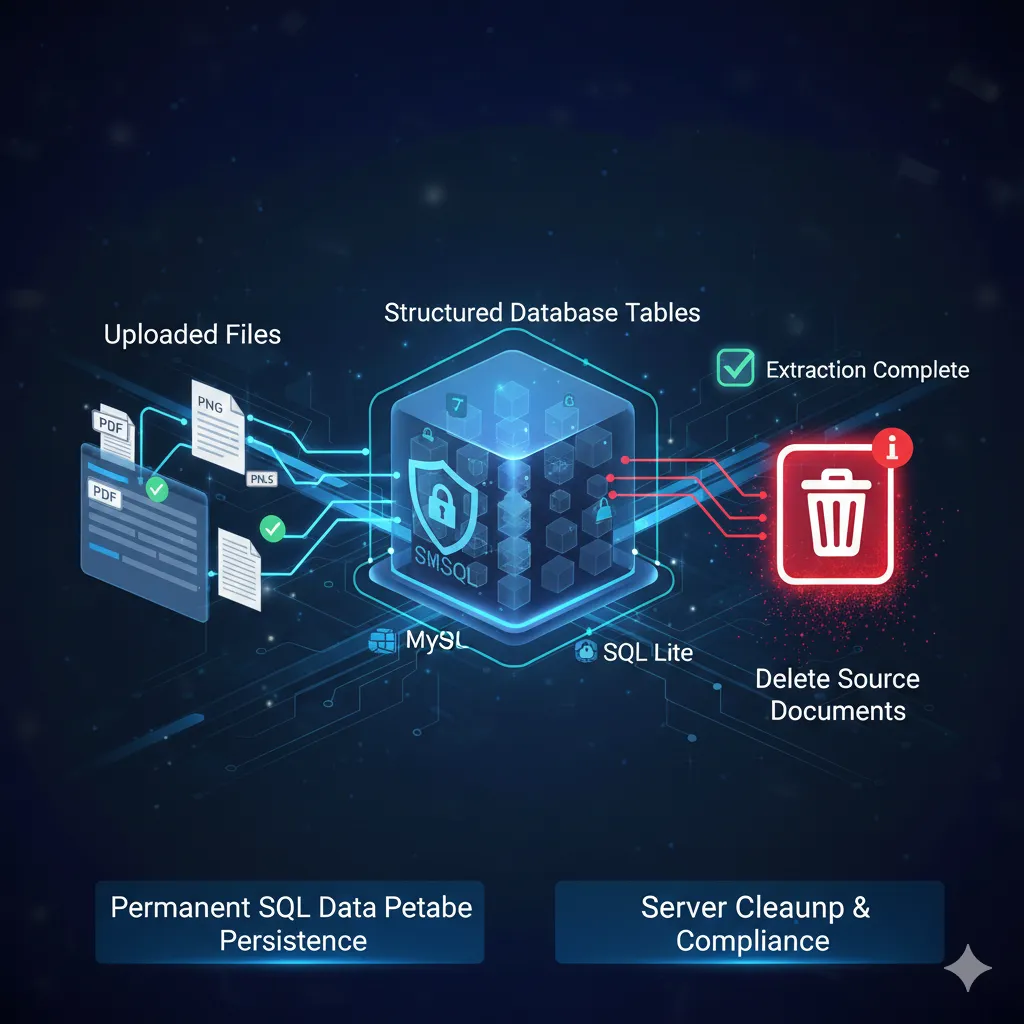
Extracted intelligence is stored permanently in structured database tables , eliminating the need to retain original source documents on the server after processing.
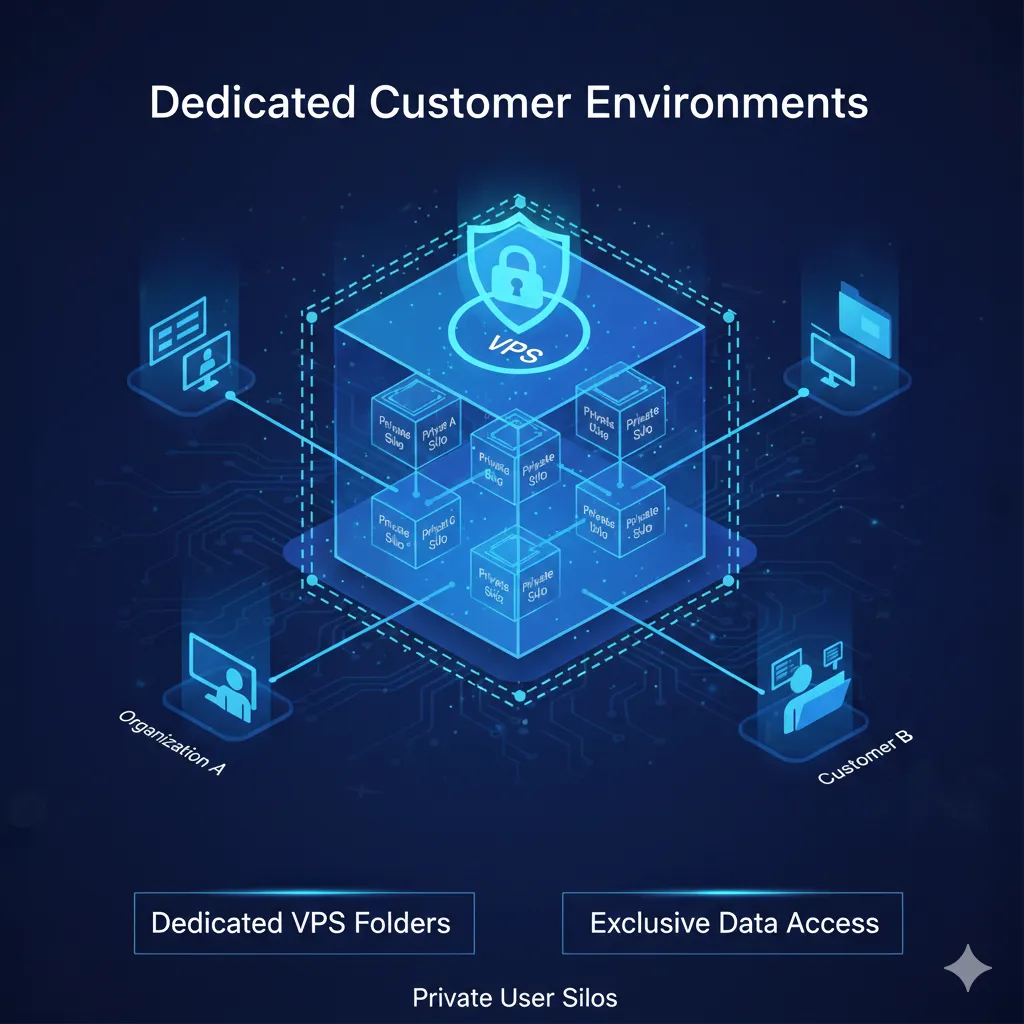
Every registered organization is assigned a unique root directory on LOCAL OR CLOUD Server, ensuring complete data isolation and preventing cross-user access.

Source documents are only required at the initial stage to define key-value anchors. Once the template is defined, source files can be removed immediately
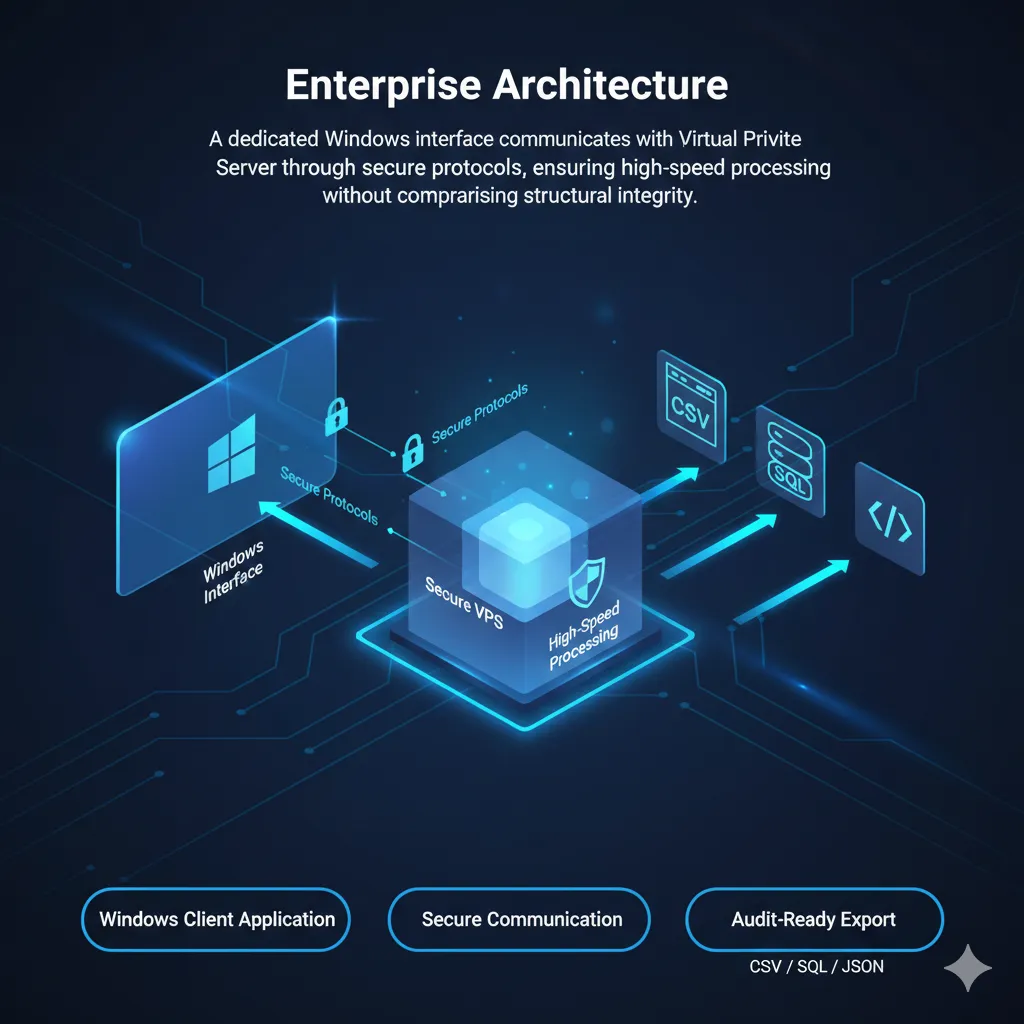
A dedicated Windows interface communicates with the Virtual Private Server through secure protocols, ensuring high-speed processing without compromising structural integrity.
OMCARA operates on a 'Transient Processing' model. Your files stay on your LOCAL MAchine or on CLOUD VPS only as long as you need them. Once the Structured™ Logic converts your documents into MySQL assets, you hold the 'Master Delete' key to wipe the server clean.